新智元GPT迭代成本「近乎荒谬」,Karpathy 300行代码带你玩转迷你版
本文插图
上周 Andrej Karpathy 发布了一个最小 GPT 实现的项目, 短短一周就收获了4200星 。
本文插图
从代码来看 , 他的minGPT实现确实精简到了极致 , 利用Karpathy的代码 , 你只需要实例化一个GPT模型 , 定好训练计划就可以开始了 , 整个实现只有300行PyTorch代码 。
本文插图
但是最有趣的部分是300行代码背后的故事 。 特别是在说明文档末尾 , 他解构了GPT-3的各种参数:
本文插图
GPT-3:96层 , 96个头 , d _ 模型12,288(175B 参数) 。GPT-1-like: 12层 , 12个头 , d _ 模型768(125M参数) GPT-3使用与 GPT-2相同的模型和架构 , 包括修改后的初始化方法等 。 在transformer层使用交替密集和局部稀疏注意力 , 类似于稀疏 Transformer 。 前馈层是瓶颈层的四倍 , 即 dff = 4 * dmodel 。 所有模型都使用 nctx = 2048 token的上下文窗口 。Adam 的参数 β1 = 0.9, β2 = 0.95, eps = 10^?8 。前3.75亿token用线性 LR 预热 , 剩下的2600亿token用余弦衰减法将学习率降至其值的10% 。 「近乎荒谬」的迭代成本让GPT调参陷困境 GPT-3的工程师们是如何确定学习速率的 , 以及其他的7个超参数 + 架构? GPT-3迭代成本相当高(一次训练可能需要几天到一周) 。 选择正确的超参数对于算法的成功至关重要 , 如果够幸运 , 模型的复杂度不高 , 可以使用超参数搜索方法 。
本文插图
超参数的搜索 事实上 , 许多研究人员都注意到 , 其实可以将其他问题中「穷举搜索」到的许多参数保持在冻结状态 , 并将搜索的复杂性降低到一些关键参数 , 如学习速率 。另一方面 , 考虑到 GPT-3的庞大规模和训练成本 , 显然OpenAI 的研究人员不可能通过超参数搜索来获得结果 , 单次训练可能花费数百万美元 。那么 , 在这种「近乎荒谬」的迭代成本范式中 , 研究人员如何确定最终确定这些参数呢?
本文插图
在训练过程中是否有干扰 , 比如在检查点重新设置并重新开始?是否会用过超参数搜索越来越大的模型 , 然后猜测超参数的大致范围? 当真正的迭代不可能时 , 如何继续AI模型的训练?相信很多人工智能的研究者有类似的疑问 , 很多训练调参还是要靠「直觉」 。但是GPT-3这种大规模模型的成功 , 是不是用了什么更科学的方法? 算力无限时 , 模型性能不再「严重依赖」超参数OpenAI其实发表过一篇论文 , 探讨了如何更好地训练GPT这类语言模型 。随着模型大小 , 数据集集大小和用于训练的计算资源增加 , 语言模型的性能总是平稳提高的 , 为了获得最佳性能 , 必须同时放大所有三个因素 。 当另外两个因素没有限制时 , 模型性能与每个因素都有幂律关系 。
本文插图
GPT3的工程师们用非常小的模型做了大量的测试 , 找到了相关的缩放曲线来决定如何分配计算/数据/模型大小 , 以便在给定的预算下获得最佳性能 , 他们检查了以前在transformer上的超参数设置和架构选择, 发现 GPT 对前者相对不敏感 , 应该扩大数据范围 , 以饱和 GPU 的吞吐量 。模型性能依赖于规模 , 它由三个因素组成:模型参数N的数量(不包括嵌入) , 数据集D的大小以及训练所用计算资源C 。结果显示 , 在合理的范围内 , 性能模型的体系结构参数依赖较小 , 例如模型的深度与宽度 。只要同时扩大N和D的规模 , 性能就会显著地提高 , 但是如果N或D保持不变而另一个因素在变 , 则进入性能收益递减的状态 。 性能损失大致取决于N^0.74 / D的比率 , 这意味着每次我们将模型大小增加8倍时 , 我们只需将数据增加大约5倍即可避免损失 。







推荐阅读






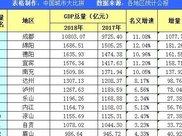







- 方便食品|方便食品产业加速迭代创新 “螺蛳粉”“自热食品”成新增长点
- 信用飞邱冠宇:消费需求迭代升级,智慧航空时代或将开启
- 方便|方便食品产业加速迭代创新,“螺蛳粉”“自热食品”成新增长点
- 方便|方便食品产业加速迭代创新 “螺蛳粉”“自热食品”成新增长点
- 宝石流云|程序员:常用的 Iterator 中的迭代器模式
- 自热|方便食品产业加速迭代创新 “螺蛳粉”“自热食品”成新增长点
- 螺蛳|方便食品产业加速迭代创新 “螺蛳粉”“自热食品”成新增长点
- 平台迭代之下 网络亚文化何去何从
- GPT-3开始探索付费使用:每月700块,写得比莎士比亚还多
- 市场|行业迭代创新 千亿级方便面市场呼之欲出。