гҖҺйҮҸеӯҗдҪҚгҖҸжҺЁзҗҶжҖ§иғҪжҜ”第дәҢеҗҚеҝ«5еҖҚпјҢйҳҝйҮҢе…¬ејҖж ёеҝғжҠҖжңҜпјҡеҰӮдҪ•ж‘ҳдёӢ4йЎ№дё–з•ҢеҶ еҶӣ( дәҢ )
жӯӨеүҚзҡ„дё–з•ҢзәӘеҪ•жүҖйҮҮз”Ёзҡ„йӣҶзҫӨ规模д№ҹжҳҜ128еј V100 пјҢ зҪ‘з»ңйҖҡдҝЎеҲҷдёә100GInfiniBandзҪ‘з»ң пјҢ жҳҜжң¬ж¬Ўжү“з ҙдё–з•ҢзәӘеҪ•зҡ„32GVPCзҡ„3еҖҚзҡ„еёҰе®Ҫ гҖӮ ејӮжһ„и®Ўз®—дә‘жңҚеҠЎзҡ„е…ёеһӢзҪ‘з»ңй…ҚзҪ®дёә32GbpsеёҰе®Ҫзҡ„VPCзҪ‘з»ң пјҢ дёәдәҶжӣҙиҙҙиҝ‘жңҖз»Ҳз”ЁжҲ·зҡ„еңәжҷҜ пјҢ йҳҝйҮҢйҖүжӢ©зҡ„жҳҜVPCзҪ‘з»ң гҖӮ
32GVPCзҪ‘з»ңдёҺеүҚдё–з•ҢзәӘеҪ•зҡ„зҪ‘з»ңзү©зҗҶеёҰе®ҪдёҠзҡ„е·ЁеӨ§е·®и·қжҳҜеӣўйҳҹйқўдёҙзҡ„йҮҚеӨ§жҢ‘жҲҳ пјҢ жҲ‘们д»ҺдёӨдёӘеӨ§зҡ„ж–№еҗ‘дҪңдәҶж·ұе…Ҙзҡ„дјҳеҢ–пјҡ
第дёҖдёӘж–№еҗ‘жҳҜд»ҺжЁЎеһӢжң¬иә«зҡ„дјҳеҢ–дёҠ пјҢ иҝӣиЎҢи¶…еҸӮзҡ„и°ғж•ҙд»ҘеҸҠoptimizerзҡ„ж”№иҝӣ пјҢ еҮҸе°‘иҫҫеҲ°93%зІҫеәҰжғ…еҶөдёӢжүҖйңҖиҰҒиҝӣиЎҢзҡ„иҝӯд»Јж•° пјҢ еҗҢж—¶д№ҹиҰҒе°ҪеҠӣжҸҗеҚҮеҚ•жңәзҡ„жҖ§иғҪ гҖӮ
第дәҢдёӘж–№еҗ‘жҳҜеҲҶеёғејҸжҖ§иғҪдјҳеҢ– пјҢ жҲ‘们йҮҮз”ЁеӣўйҳҹиҮӘз ”зҡ„йЈһеӨ©AIеҠ йҖҹеј•ж“ҺAIACC-TrainingпјҲеҺҹAli-Perseus-TrainingпјүдҪңдёәеҲҶеёғејҸзҡ„йҖҡдҝЎеә“ пјҢ е……еҲҶжҢ–жҺҳ32GVPCзҡ„жүҖжңүжҪңеҠӣ гҖӮ
жңҖз»ҲдёӨдёӘж–№еҗ‘зҡ„жһҒиҮҙдјҳеҢ–зӣёеҸ еҠ пјҢ и¶…и¶ҠдәҶдёҖдёӘзңӢдјјдёҚеҸҜиғҪиҫҫеҲ°зҡ„жҖ§иғҪеұҸйҡң пјҢ д»ҘиҫғдҪҺзҡ„зҪ‘з»ңеёҰе®Ҫ пјҢ еҲӣйҖ дәҶж–°зҡ„дё–з•ҢзәӘеҪ• гҖӮ
еҗҢж—¶ пјҢ еӣ дёәеҲҶеёғејҸи®ӯз»ғйғЁзҪІжң¬иә«зҡ„еӨҚжқӮжҖ§ пјҢ дёәдәҶжҸҗй«ҳж•ҲзҺҮ пјҢ д№ҹдёәдәҶж–№дҫҝеӨ–йғЁз”ЁжҲ·йҮҚзҺ°з»“жһң пјҢ йҳҝйҮҢеӣўйҳҹдҪҝз”ЁдәҶд№ӢеүҚејҖеҸ‘зҡ„еҚіеҲ»жһ„е»әзҡ„е·Ҙе…·FastGPU пјҢ е°ҶйӣҶзҫӨзҡ„еҲӣе»әе’ҢеҲҶеёғејҸи®ӯз»ғзҡ„и°ғеәҰе…ЁйғЁд»Ҙи„ҡжң¬зҡ„ж–№ејҸе®ҢжҲҗ пјҢ еҸҜд»ҘдёҖй”®еҗҜеҠЁ пјҢ еӨ§еӨ§еҠ еҝ«дәҶдјҳеҢ–е·ҘдҪңзҡ„ж•ҲзҺҮ гҖӮ
жңӘжқҘ пјҢ жҲ‘们дјҡејҖжәҗеҹәдәҺAIACCзҡ„benchmarkд»Јз Ғ пјҢ ж–№дҫҝеӨ–йғЁз”ЁжҲ·дёҖй”®еӨҚзҺ°з»“жһң гҖӮ
еҲҶеёғејҸи®ӯз»ғйўҶеҹҹиҝ‘е№ҙжқҘеҸ‘еұ•иҝ…зҢӣ пјҢ жңүеӨҡз§ҚеҸҜдҫӣйҖүжӢ©зҡ„и§ЈеҶіж–№жЎҲ пјҢ еҜ№дәҺTensorflowиҖҢиЁҖ пјҢ жЎҶжһ¶жң¬иә«ж”ҜжҢҒPSжЁЎејҸд»ҘеҸҠRingallreduceйЈҺж јзҡ„еҲҶеёғејҸйҖҡдҝЎ пјҢ 第дёүж–№зҡ„ж”ҜжҢҒжңүHorovod гҖӮ
еҜ№дәҺResNet50зҡ„еҲҶеёғејҸи®ӯз»ғ пјҢ ејҖжәҗж–№жЎҲдёӯHorovodдҫқ然жҳҜзӣёеҜ№жңҖдјҳзҡ„и§ЈеҶіж–№жЎҲ пјҢ еӣ жӯӨ пјҢ йҳҝйҮҢд»ҘHorovodдҪңдёәеҜ№жҜ”зҡ„baseline гҖӮ
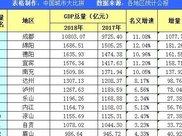
еҲҶеёғејҸи®ӯз»ғзҡ„йҖ»иҫ‘жЎҶеӣҫеҰӮдёӢеӣҫжүҖзӨәпјҡ

ж–Үз« еӣҫзүҮ
жңҖе°Ҹи®Ўз®—иҠӮзӮ№дёәеҚ•еј GPUеҚЎ пјҢ жҜҸдёӘи®Ўз®—иҠӮзӮ№йғҪдјҡд»ҺжҖ»зҡ„ж•°жҚ®йӣҶдёӯеҲ’еҲҶдёҖд»Ҫж•°жҚ®дҪңдёәжң¬иҠӮзӮ№зҡ„и®ӯз»ғж•°жҚ® пјҢ 然еҗҺејҖе§ӢеүҚеҗ‘е’ҢеҗҺеҗ‘зҡ„и®Ўз®— пјҢ еңЁеҗҺеҗ‘и®Ўз®—з»“жқҹеҗҺдјҡеҫ—еҲ°еҪ“еүҚbatchжүҖдә§з”ҹзҡ„жўҜеәҰ гҖӮ
然еҗҺеңЁжӣҙж–°еҸӮж•°д№ӢеүҚ пјҢ йңҖиҰҒеңЁж•ҙдёӘйӣҶзҫӨдёҠиҝӣиЎҢжўҜеәҰйҖҡдҝЎ гҖӮ HorovodAPIе°ұжҳҜеңЁжўҜеәҰжӣҙж–°д№ӢеүҚ пјҢ еңЁoptimizerиҝҷдёӘзҺҜиҠӮжҸ’е…ҘдәҶдёҖж®өеӨҡиҠӮзӮ№й—ҙзҡ„йҖҡдҝЎзҡ„жөҒзЁӢ гҖӮ
AIACC-TrainingAIACC-TrainingжҳҜйҳҝйҮҢдә‘иҮӘз ”зҡ„ж·ұеәҰеӯҰд№ еҲҶеёғејҸи®ӯз»ғйҖҡдҝЎеј•ж“Һ пјҢ з»ҹдёҖж”ҜжҢҒTensorflowгҖҒPyTorchгҖҒMxNetе’ҢCaffe пјҢ д»ҺIaaSеұӮйқўжҸҗдҫӣеҸҜиў«йӣҶжҲҗдё”е…је®№ејҖжәҗзҡ„еҠ йҖҹеә“ гҖӮ
зҺ°еңЁе·Із»ҸжңүеӨҡ家AIе’Ңдә’иҒ”зҪ‘е®ўжҲ·еңЁз”ҹдә§зҺҜеўғдёӯеӨ§йҮҸйғЁзҪІдҪҝз”Ё пјҢ жҳҫи‘—жҸҗеҚҮејӮжһ„и®Ўз®—дә§е“Ғзҡ„жҖ§д»·жҜ” пјҢ д»ҺиҪҜ件еұӮйқўдёәе®ўжҲ·жҸҗдҫӣе·®ејӮеҢ–зҡ„и®Ўз®—жңҚеҠЎ пјҢ жһ¶жһ„еҰӮдёӢеӣҫжүҖзӨә гҖӮ

ж–Үз« еӣҫзүҮ
AIACC-TrainingдҪңдёәжӯӨж¬ЎDawnbenchи®°еҪ•зҡ„еҲҶеёғејҸеҗҺз«Ҝ пјҢ еҸ‘жҢҘдәҶиҮіе…ійҮҚиҰҒзҡ„дҪңз”Ё гҖӮ д»ҘдёӢжҳҜжҲ‘们еҜ№AIACC-TrainingиғҢеҗҺзҡ„еҲҶеёғејҸдјҳеҢ–дҪңиҜҰз»Ҷзҡ„и§Јжһҗ гҖӮ
еҺ»дёӯеҝғеҢ–жўҜеәҰеҚҸе•ҶеҲҶеёғејҸжҖ§иғҪзҡ„е…ій”®е°ұжҳҜеҰӮдҪ•дјҳеҢ–иҝҷдёӘйҖҡдҝЎзҺҜиҠӮзҡ„ж•ҲзҺҮ пјҢ еҜ№дәҺResNet50иҖҢиЁҖ пјҢ жҲ‘们йңҖиҰҒйҖҡдҝЎзҡ„жўҜеәҰж•°жҚ®еӨ§зәҰжҳҜ170дёӘ пјҢ иҖҢйҖҡдҝЎзҡ„жҖ»йҮҸеӨ§зәҰжҳҜ50MB гҖӮ
иҝҷдәӣжўҜеәҰзҡ„дә§з”ҹж—¶жңәдҫқиө–дәҺе®ғ们еҗ„иҮӘеңЁи®Ўз®—еӣҫдёӯзҡ„дҪҚзҪ® пјҢ и®Ўз®—еӣҫдёӯеӯҳеңЁдҫқиө–е…ізі»зҡ„йғЁеҲҶжўҜеәҰеҶіе®ҡдәҶиҝҷдёҖйғЁеҲҶжўҜеәҰиў«и®Ўз®—еҮәжқҘзҡ„ж—¶й—ҙе…ҲеҗҺйЎәеәҸ гҖӮ
иҖҢеңЁи®Ўз®—еӣҫдёӯеӨ„дәҺзӣёдә’д№Ӣй—ҙе®Ңе…Ёж— дҫқиө–зҡ„з®—еӯҗзҡ„ пјҢ е®ғ们еңЁжҜҸж¬Ўи®Ўз®—еҸ‘з”ҹзҡ„ж—¶жңәе…·жңүдёҖе®ҡзҡ„йҡҸжңәжҖ§ гҖӮ еңЁеӨҡиҠӮзӮ№й—ҙйҖҡдҝЎиҰҒи§ЈеҶізҡ„第дёҖдёӘй—®йўҳе°ұжҳҜйңҖиҰҒеҚҸе•ҶжўҜеәҰзҡ„еҗҢжӯҘйЎәеәҸ гҖӮ
HorovodдёӯжүҖйҮҮз”Ёзҡ„зҡ„ж–№жі•жҳҜд»Ҙ0еҸ·иҠӮзӮ№дёәдёӯеҝғ пјҢ дёҺжүҖжңүе…¶е®ғиҠӮзӮ№иҝӣиЎҢзӮ№еҜ№зӮ№зҡ„йҖҡдҝЎзЎ®е®ҡеҪ“еүҚжүҖжңүиҠӮзӮ№дёҠйғҪе·Із»Ҹе°ұз»Әзҡ„жўҜеәҰ пјҢ 然еҗҺеҶҚ0еҸ·иҠӮзӮ№дёҠзЎ®е®ҡиҝҷдәӣе°ұз»ӘжўҜеәҰдёҠеҰӮдҪ•еҺ»йҖҡдҝЎ пјҢ жңҖеҗҺе°ҶйҖҡдҝЎзӯ–з•ҘзӮ№еҜ№зӮ№зҡ„еҸ‘йҖҒеҲ°жҜҸдёҖдёӘе…¶е®ғиҠӮзӮ№ пјҢ д№ӢеҗҺж №жҚ®йҖҡдҝЎзӯ–з•ҘејҖе§ӢиҝӣиЎҢеӨҡжңәйҖҡдҝЎ гҖӮ
жҺЁиҚҗйҳ…иҜ»













- еҸҜеҸҜй…ұ75еҗӢйҮҸеӯҗзӮ№з”өи§Ҷи®©еӯ©еӯҗеҒҘеә·жҲҗй•ҝпјҢеҰӮдҪ•жүҚиғҪеҒҘеә·дёҚдјӨзңјзҡ„зңӢз”өи§ҶпјҹTCL
- дёӯеӣҪжҷәиғҪеҲ¶йҖ зҪ‘йҮҸеӯҗйҖҡдҝЎеёғеұҖиө·йЈҺдәҶпјҒпјҢеӨҡеӣҪе·ІжңӘйӣЁз»ёзјӘ
- гҖҢйҮҸеӯҗеҠӣеӯҰгҖҚзҲұеӣ ж–ҜеқҰд№ҹжқҹжүӢж— зӯ–пјҢеӣ°жү°дәәзұ»дёҠзҷҫе№ҙзҡ„йҡҫйўҳпјҢеҰӮд»Ҡз»ҲдәҺжңүдәҶзӯ”жЎҲ
- гҖҺйҮ‘еӯ—еЎ”гҖҸеҸҜиғҪжҜ”йҮ‘еӯ—еЎ”жӣҙеҸӨиҖҒзҡ„иҝңеҸӨйҒ—иҝ№пјҢиҝҷдәӣеӨұиҗҪзҡ„ж–ҮжҳҺдёҺдәәзұ»жңүе…ізі»еҗ—пјҹ
- дёҺеҚ•и§Ӯз»Ҹ欧зӣҹзһ„еҮҶвҖңйҮҸеӯҗдә’иҒ”зҪ‘вҖқйҷ„зӣёе…іжҰӮеҝөиӮЎ
- е№ҝдёңеңҶжўҰеӣӯеӯөеҢ–еҹҺгҖҗеӣӯеҢәеҠЁжҖҒгҖ‘е№ҝдёңзңҒйҮҚзӮ№йўҶеҹҹз ”еҸ‘и®ЎеҲ’йҮҸеӯҗ科еӯҰдёҺе·ҘзЁӢйҮҚеӨ§дё“项专家组иҺ…дёҙеӣӯеҢәиҖғеҜҹжҢҮеҜј
- гҖҢеҢ–зҹігҖҚиҪ¬з”ҹе°ҶеҸҜиғҪжҳҜдёҖ件зңҹдәӢпјҢйҮҸеӯҗеҠӣеӯҰзҡ„жңҖж–°еҸ‘зҺ°пјҢ科еӯҰ家д№ҹиў«йңҮж’ј
- cnBetaеҫ®иҪҜз ”з©¶дәәе‘ҳж”»е…ӢдәҶдёӨдёӘе·Іжңү20е№ҙеҺҶеҸІзҡ„йҮҸеӯҗи®Ўз®—й—®йўҳ
- жҳҹзҒ«ж–№еқ—| зўізәізұіз®ЎиҚ§е…үйҮҸеӯҗж•ҲзҺҮз ”з©¶еҸ–еҫ—иҝӣеұ•пјҢиҝӣеұ•
- еӨ§зүӣеҘҺе“Ҙпјҡе…іжіЁдә§дёҡй“ҫзҡ„жҠ•иө„жңәдјҡпјҒпјҢйҮҸеӯҗйҖҡдҝЎпјҡејҖеҗҜжңӘжқҘдҝЎжҒҜжҠҖжңҜд№Ӣдәү